
Vetric Instagram User Feed
Retrieve Instagram posts from the user's feed
The Vetric Instagram User Feed allows you to return items from the user feed by his user id.
The complete Vetric documentation about their endpoint can be found in their site here.
New to Datastreamer? Start here.
Unify SchemaThis data source already use Unify Schema.
API Key
You will need a Vetric API key to use this component. If you don't have one reach out to [email protected] and our team will help you with that.
How To Use?
The component is powered by the Jobs System, when interacting with the component you have the option to define your jobs queries.
Search Query
Filters
| Filter Name | Description |
|---|---|
| user_id | Instagram user ID |
| query_from | Filter dates from/since - Example '2024-05-01T00:00:00Z' |
| query_to | Filter dates to - Example '2024-08-01T00:00:00Z' |
| max_documents | Set a limit for the number of documents that will be fetched for the search. |
| max_excess_documents | When filtering by date, this sets the limit of documents to process that fall outside the date range. This serves as a cost-control measure. Note that costs apply for all retrieved documents, including those that are discarded. |
Since the Vetric endpoint does not natively support date filtering, the query_from and query_to filters are applied in memory. Because we cannot guarantee how many documents must be retrieved to find those within the desired date range, the max_excess_documents field can be used to limit the number of documents processed.
Examples
Retrieve posts from feed
Retrieve posts from feed of the user with id '184692323'.
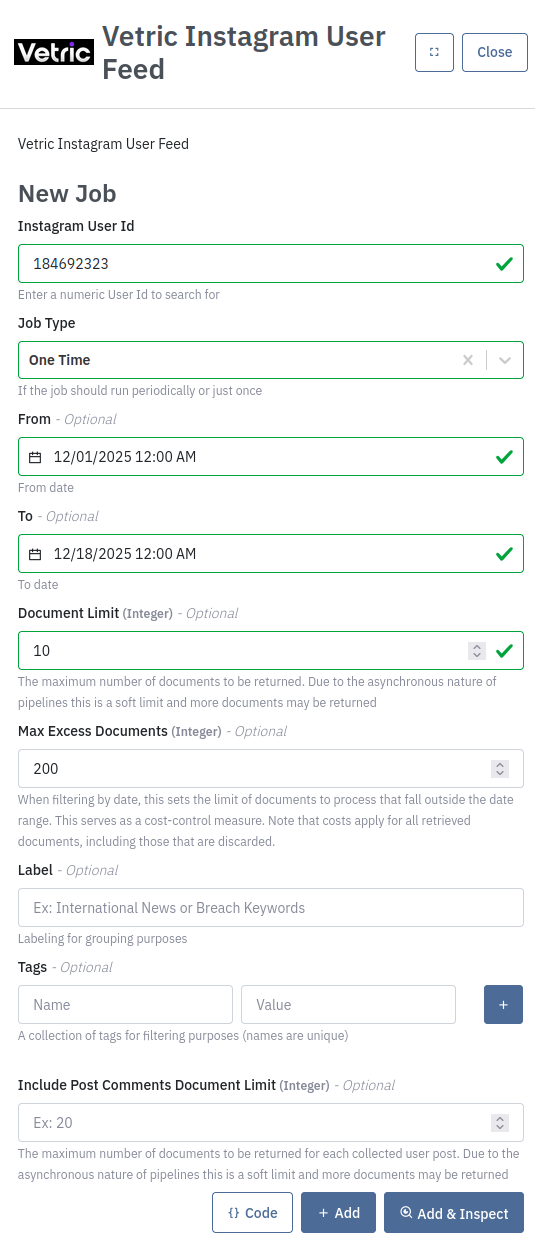
You also have the option to use the API. You can use the Code button to extract this example:
curl --location 'https://api.platform.datastreamer.io/api/pipelines/{PIPELINE_ID}/components/{COMPONENT_ID}/jobs?ready=true' \
--header 'apikey: <your-api-key>' \
--header 'Content-Type: application/json' \
--data \
'{
"job_name": "cb056187-1943-4aa3-91d1-f2fd86026edb",
"component_name": "vetric-instagram-user-feed-ingress",
"data_source": "vetric_instagram_user_feed",
"query": {
"include": [
{
"data_source": "vetric_instagram_post_comments"
}
],
"query": "184692323",
"max_excess_documents": 200
},
"job_type": "oneTime",
"query_from": "2025-12-01T00:00:00.000Z",
"query_to": "2025-12-18T00:00:00.000Z",
"max_documents": 10
}'For more details on creating data collection jobs, see Job Management.
Additional Details
Compatible Metadata Fields
| Applicable Metadata Categories | Compatible |
|---|---|
| Source | Yes |
| Content | Yes |
| Author | Yes |
| Person | No |
| Enrichment | Yes |
| Organization | No |
| Data source-specific fields? | Yes, please see the Metadata page. |
Metadata Example
{
"data_source": "vetric_instagram_user_feed",
"id": "3374748632723463942_184692323",
"doc_date": "2024-05-24T03:38:20Z",
"content": {
"published": "2024-05-24T03:38:20Z",
"body": "A POEM FOR A MONSTER\n\nIf you could walk with air under your feet\nYou’d find imagination is complete\nWith buoyancy and complicated turns\nWith heartbreak always nudging us to yearn\n\nI found a way back to myself again\nWith different tones, and metals I could bend\nI hope that you will love me in this way \nFor who I am—not then—but for today\n\n-LG\n\nOutfit by @selva________________ \nFashion Direction by @nicolaformichetti \nphoto @domenvandevelde \nstyling @hunterclem_ \nhair @fredericaspiras\nmake up @sarahtannomakeup \nnail @mihonails",
"media_id": "3374748632723463942",
"comments_count": 18133,
"likes_count": 1006342
},
"author": {
"handle": "ladygaga",
"profile_image_source": "https://instagram.fgba1-1.fna.fbcdn.net/v/t51.2885-19/436332564_1083477752743141_8056028257727506515_n.jpg?stp=dst-jpg_e0_s150x150&_nc_ht=instagram.fgba1-1.fna.fbcdn.net&_nc_cat=1&_nc_ohc=EkS-YZUOoyMQ7kNvgGgsE9Q&gid=4d3a9a3ebbd447dc8df7dd72c473ec90&edm=ABmJApABAAAA&ccb=7-5&oh=00_AYD8w_6dTgtCYgWn0hrVdaANe1c8xLYJt9zP6EVjYCcFkg&oe=66A5DAE6&_nc_sid=b41fef",
"verified": true,
"protected": false,
"name": "Lady Gaga",
"userid": "184692323",
"url": "https://instagram.com/ladygaga/"
},
"facebook": {
"userid": "18110591887377755"
},
"source": {
"link": "https://instagram.com/p/C7VhABTt58G/"
}
}Data collection job creation request
Returns matched Instagram User Id feed. The query value is expected to be a valid Instagram User Id (can be obtained from Instagram user-search).
curl --location 'https://api.platform.datastreamer.io/api/pipelines/{PIPELINE_ID}/components/{COMPONENT_ID}/jobs?ready=true' \
--header 'apikey: <your-api-key>' \
--header 'Content-Type: application/json' \
--data \
'{
"job_name": "my instagram data collection",
"data_source": "vetric_instagram_user_feed",
"query": {
"query": "184692323"
},
"job_type": "oneTime"
}'Make sure to replace ‘PIPELINE_ID’ and ‘COMPONENT_ID’ variables to the ones associated with your pipeline.
Including post comments
Similar to previous examples on fetching Instagram user posts, it is possible to include comments found on each of the user posts fetched.
Data Collection Job Example
This job query will fetch up to 10 Instagram Posts for user id '787132', then include up to 5 Comments from each of the 10 posts found.
NoteYou can specify the
max_documentsparameter to control the volume of data retrieved in both the main and included queries.
curl --location 'https: //api.platform.datastreamer.io/api/pipelines/{PIPELINE_ID}/components/{COMPONENT_ID}/jobs?ready=true' \
--header 'apikey: <your-api-key>' \
--header 'Content-Type: application/json' \
--data \
'{
"job_name": "my instagram data collection",
"data_source": "vetric_instagram_user_feed",
"max_documents": 10,
"query": {
"query": "787132",
"include": [
{
"data_source": "vetric_instagram_post_comments",
"max_documents": 5
}
]
},
"job_type": "oneTime"
}'Important: Replace the PIPELINE_ID and COMPONENT_ID values with those corresponding to your pipeline.
Data Collection Job Results
The initial query run would first fetch up to 10 documents from vetric_instagram_user_feed data source
{
"documents": [
{
"data_source": "vetric_instagram_user_feed",
"id": "3465979734695597050_787132",
"doc_date": "2024-09-27T00:30:11Z",
"content": {
"published": "2024-09-27T00:30:11Z",
"body": "For the first time, scientists observed the brain of one woman throughout pregnancy—from pre-conception to postpartum—scanning her brain 26 times. \n\nThe study found that gray matter in the brain decreased by more than 4 percent during pregnancy while white matter strengthened—changes that could impact cognition, sensation, learning, and interaction with newborns.\n\nWith more than 85 percent of women experiencing pregnancy in their lifetime, understanding its effects on mental health and thinking is essential. Learn more at the link in bio.\n\nPhotograph by greg801n, Getty Images",
"media_id": "3463427961463821516",
"comments_count": 646,
"likes_count": 57155
},
"author": {
"handle": "natgeo",
"profile_image_source": "https://scontent-dfw5-1.cdninstagram.com/v/t51.2885-19/441272846_3660325754227424_608588627427268733_n.jpg?stp=dst-jpg_e0_s150x150&_nc_ht=scontent-dfw5-1.cdninstagram.com&_nc_cat=1&_nc_ohc=cyKc1c_W14wQ7kNvgErANms&_nc_gid=d71ef15ffaf044b99c4737b0cf3e7074&edm=ABmJApABAAAA&ccb=7-5&oh=00_AYDON588sTVK88A-Mq9vMzk0onqsirPXMXGJToPjTepPFw&oe=66FC8D77&_nc_sid=b41fef",
"verified": true,
"protected": false,
"name": "National Geographic",
"userid": "787132",
"url": "https://instagram.com/natgeo/"
},
"facebook": {
"userid": "18005809307466248"
},
"source": {
"link": "https://instagram.com/p/DAZojSFO9P6/"
}
}
]
}Partial Response example of collecting Instagram User Feed.
Subsequent queries then would start based on fetched user posts, where each user post, would fetch up to 5 documents from vetric_instagram_post_comments source, by matching the user post.
{
"documents": [
{
"data_source": "vetric_instagram_post_comments",
"id": "18019083575265676",
"author": {
"userid": "28569666463",
"handle": "qbangrl13",
"name": "ɐɯıəʎ",
"profile_image_source": "https://scontent-dfw5-1.cdninstagram.com/v/t51.2885-19/460686175_1555771215366982_2989984919338633558_n.jpg?stp=dst-jpg_e0_s150x150&_nc_ht=scontent-dfw5-1.cdninstagram.com&_nc_cat=110&_nc_ohc=pMblR8AEHKQQ7kNvgH7Gvtv&edm=AId3EpQBAAAA&ccb=7-5&oh=00_AYBjMp-YqZZNWAiucGjQbOk6p5Y3SctYV8jCv4PBtn910Q&oe=66FC88F0&_nc_sid=f5838a",
"verified": false,
"is_mentionable": false,
"url": "https://www.instagram.com/qbangrl13"
},
"doc_date": "2024-09-23T12:37:44.000Z",
"content": {
"published": "2024-09-23T12:37:44.000Z",
"body": "I have four.. been keeping them since I was a teenager. I love these lil guys ❤️",
"likes_count": 1,
"child_comments_count": 0,
"related_post_id": "3463427961463821516"
},
"instagram": {
"content_type": "comment"
}
}
]
}Important: Only a single include object can be requested per query.
Updated 5 months ago