
Creating Your First Pipeline
Not sure what a "pipeline" or "component" is?If you are not yet familiar with "pipelines" and "components" it is highly suggested to first read through the pages in the "Getting Started" section of the documentation.
Introduction to Portal
Portal is a UI layer on the Datastreamer platform that allows you to easily generate pipelines, manage them, and handle billing/detailed customization. Portal is used for the initial creation of Pipelines due to the detailed information and configuration present.
Once you deploy a Pipeline from Portal, you can interact with the input/output through APIs directly.
Portal is accessible at portal.datastreamer.io
Creating a Pipeline
- Navigate to the Pipelines screen
Sidebar within Portal
- Create a New Pipeline
On this screen you will be able to see all of your pipelines. To create a new one, click "New Pipeline" on the presented screen.
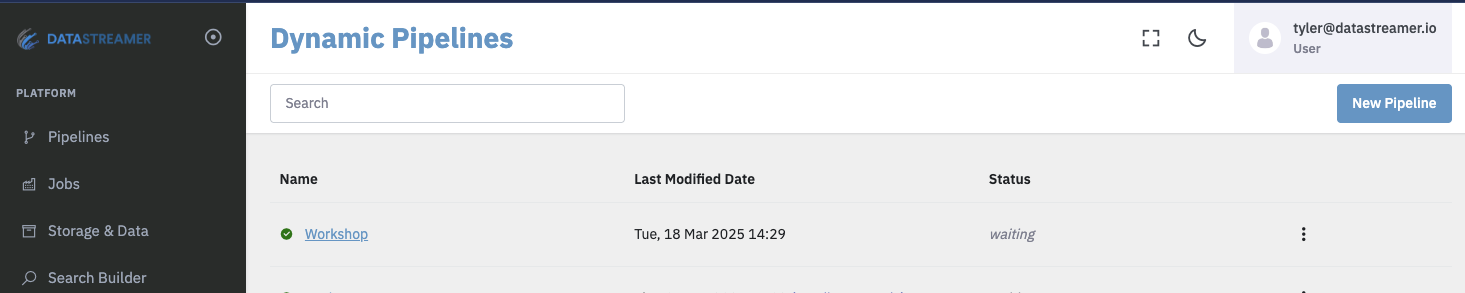
Dynamic Pipelines screen
- Start adding components to your Pipeline canvas.
Selecting the (+) will open a sidebar with hundreds of prebuilt components ready-to go!
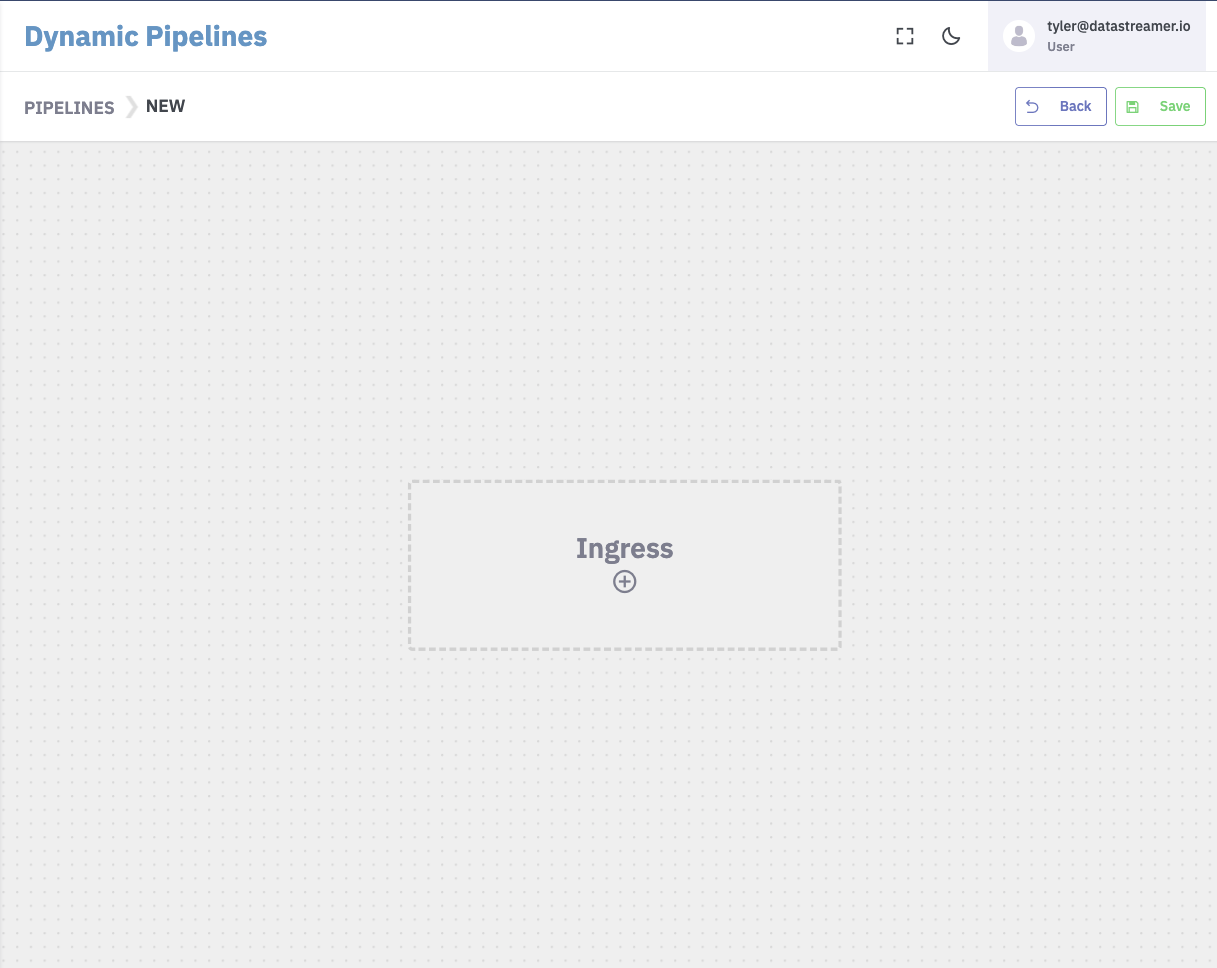
New Pipeline canvas
- Finish configuration of the components to deploy.
Components that are configured will show a green "Configured" button, while components requiring configuration will show yellow as shown below.
You can add, modify, delete any number of components to meet your required use cases.
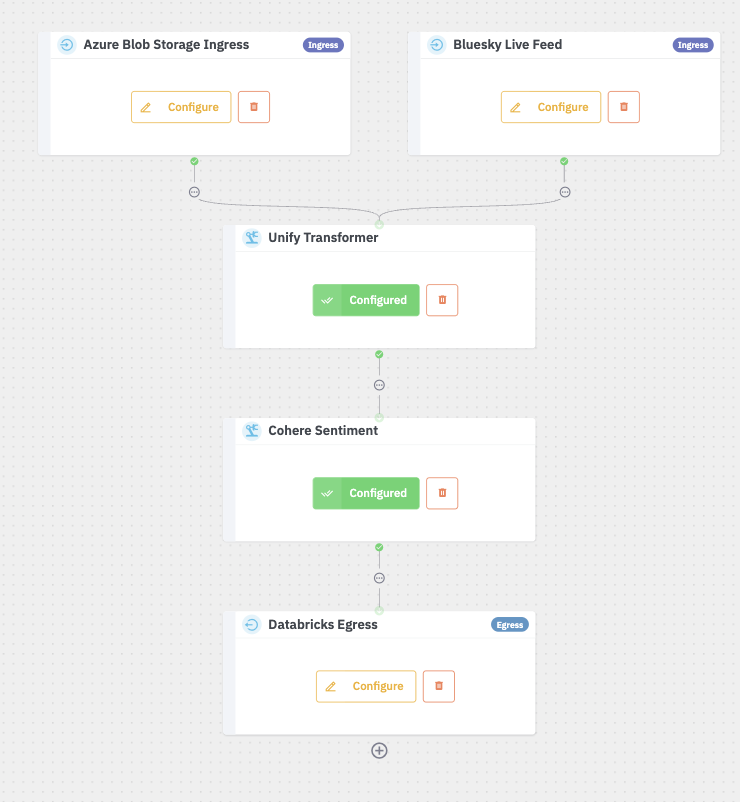
- Deploy
Once all required steps have been configured, the "Save" button in the top right will be joined by a "Deploy" button. Selecting Deploy will turn your Pipeline into a production-ready pipeline.

Options on an draft Pipeline ready for deployment
The options at the top will now update to show new options to manage your Pipeline. As this is a "Dynamic Pipeline" you can edit, add new capabilities and upgrade to the newest version without any downtime or data interruption!

Options on a deployed Pipeline ready for an upgrade
All set!
You've now deployed your first Pipeline! Here are some suggested next steps for a more detailed start:
- Applying a data schema
- Creating Jobs to ingest data
- Feeding data directly into the Pipeline
- Applying operations to the data.