
Document Deduplication
If you're using Datastreamer Searchable Storage, documents are automatically deduplicated based on their id field.
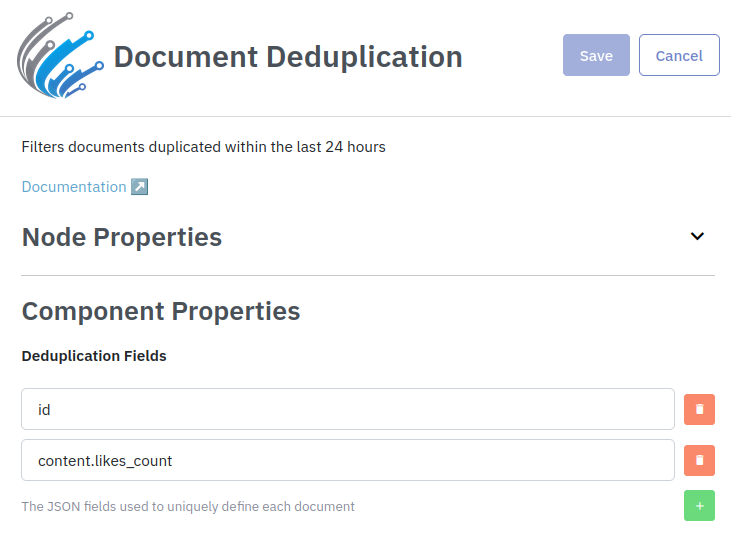
For clients not using Datastreamer Searchable Storage, similar deduplication can be achieved by including the Document Deduplication connector from the catalog. This component filters out duplicates within a 24-hour window.
By default, the connector uses the id field in each JSON document to identify duplicates. However, this may unintentionally filter out important updates (e.g., changes in social media engagement). To avoid this, you can specify additional fields when configuring the connector, allowing meaningful updates to pass through.
Updated about 1 month ago
Did this page help you?