
Datastreamer Searchable Storage Ingress
Reads data from existing searchable storages using Lucene queries
With the Datastreamer Searchable Storage Ingress component added to your pipeline, you can read the content of any of your current searchable storages created by the Datastreamer Searchable Storage Egress (displayed in the Storage & Data page).
Component Configuration
After adding the Datastreamer Searchable Storage Ingress to your Pipeline and starting its configuration, you will see the Job setup:
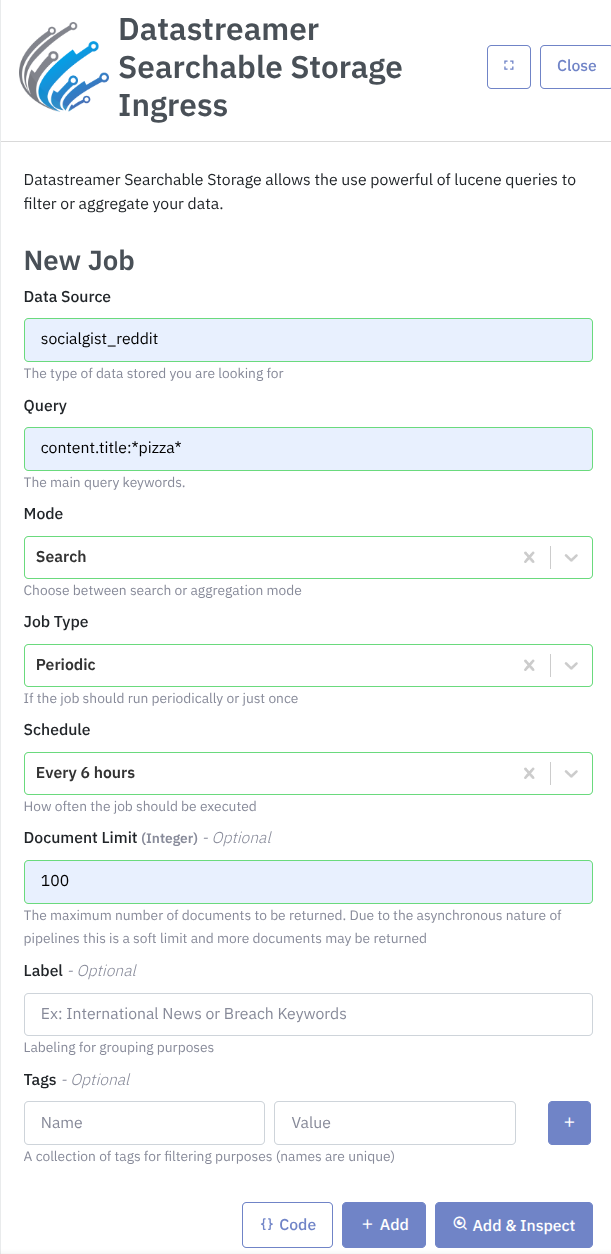
Below is quick and easy explanation of how to fill out each important field:
- In the Data Source field, enter the name of your Searchable Storage from Storage & Data page.
- In the Query field, enter the Lucene query that you want to execute against the Searchable Storage. You can test the query directly in your storage before using it in the Job.
- Query example:
content.title:*pizza* AND content.followers:{72470 TO *} - The available fields will be determined by the content that you have in the storage.
- Query example:
- In the Mode field, you can choose between:
- Search: in the Search mode, the query will run, and you will receive the documents that match the query.
- Aggregation: in the Aggregation mode, you are able to provide not just the query but also the aggregation query in JSON format. This aggregation query will be used for the Elasticsearch to run the aggregation. The result of this operation will be the
buckets.
The fields Job Type, Document Limit, Label and Tags follow the same logic as in other component jobs.
Adding the Job, it will be executed upon deployment.
About Aggregation
The Aggregations mode allow you to do an analytical operations that summarize your data rather than returning individual documents. Instead of sifting through thousands or millions of individual documents, aggregations allow you to group your data and perform calculations on these groups.
As example, see this aggregation JSON:
{
"top_hashtags": {
"terms": {
"field": "content.hashtags.keyword",
"size": 5
}
}
}This Elasticsearch terms aggregation analyzes the content.hashtags.keyword field to identify the top 5 most frequent hashtags in matching documents. It groups documents by their exact hashtag values, counts occurrences for each unique hashtag, then returns the highest-frequency hashtags ranked by document count. This aggregation is ideal for real-time trend detection, like identifying viral topics or popular brand mentions across social media data.
The output can look like this along with a query searching for "sustainability" (content.body:sustainability):
{
"buckets": [
{"key": "sustainability", "doc_count": 2541},
{"key": "eco-friendly", "doc_count": 1893},
{"key": "green-living", "doc_count": 1672},
{"key": "climate-action", "doc_count": 1421},
{"key": "circulareconomy", "doc_count": 1289}
]
}This shows which sustainability-related hashtags people are using most. 'Sustainability' appeared in 2,541 posts - making it the most popular tag. This tells us what environmental topics customers care about right now.
Updated about 1 month ago