
WebSightLine File Fetcher
WebSightLine file fetcher downloads images into client storage automatically from JSON paths.
Usage
The File Fetcher is often used to pull the images, files, HTTP pages, and other content associated with documents in a Pipeline. It will pull the files from the provided JSON paths using a powerful proxy network and place the files in the specified storage.
Common uses:
- Fetching the PDFs in reports.
- Fetching the images from social media content.
- Fetching images from news articles.
Component Configuration
You can add and configure wsl-file-fetcher in your Pipeline by adding the component as an operation. It is recommended to use a transform operation (JSON Transform or Unify Transform) to standardize the fields before this component.
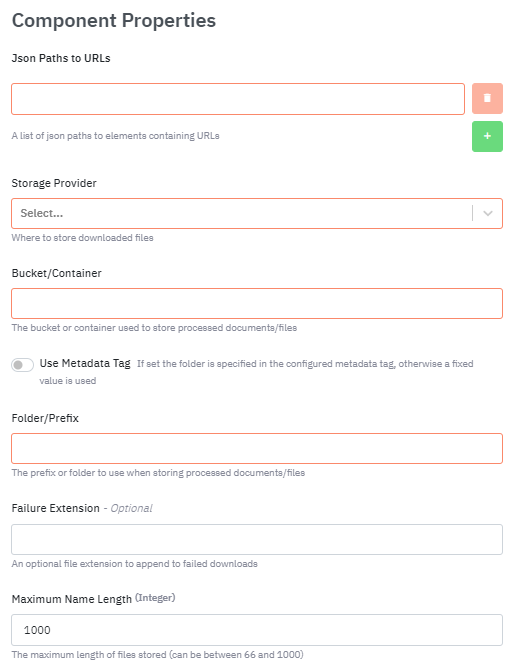
JSON Paths to URL (Required)
Images URL’s are extracted from the json document using standad “json path” rules. Multiple locations can be entered and arrays are supported. If no values are entered then the default is the standard Datastreamer image link location: content.image_urls[*]
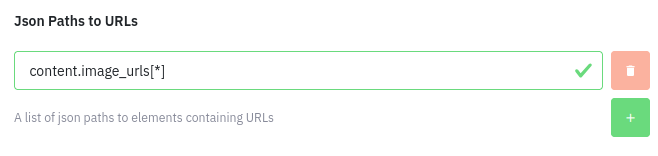
Storage Provider
The storage provider must be selected. Options are:
| Storage Provider | Description |
|---|---|
| Amazon S3 | Store files in a client managed AWS S3 Bucket |
| Azure Blob Storage | Store files in a client managed Azure Blob Container |
| Google Cloud Storage | Store files in a client managed GCS Bucket |
| Datastreamer Managed Storage | Let datastreamer store the files. |
| Temporary Cache | Files are stored in the pipeline cache and are available to downstream components that can handle files of the returned content type. |
On selection further configuration many be necessary (e.g. the azure Shared Access Token or the google Service Account)
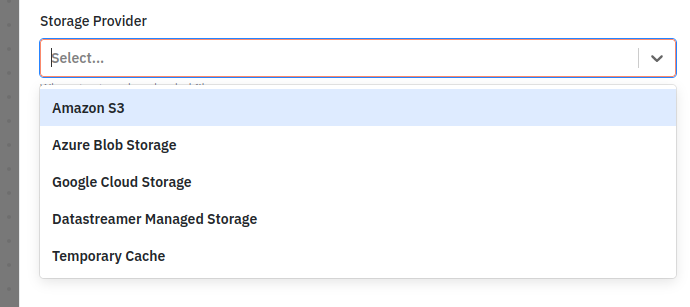
Bucket/Container
For client managed storage a bucket/container must be provided. A folder name is optional (not available on the Temporary Cache) and if set this will be the folder/prefix used to store files at the storage provider. In addition when the component is used in a pipeline with a “Job” type ingress it is possible to specify the folder when the job is created. To do this select the “Use Metadata Tag” option.
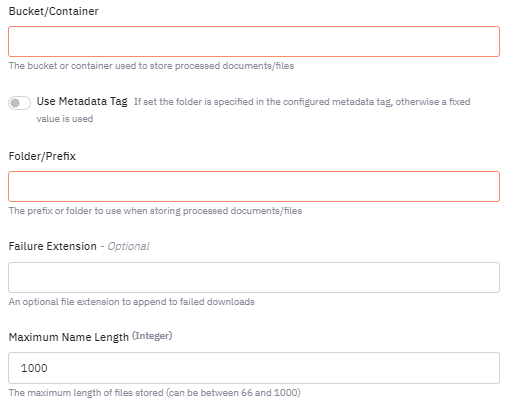
Use Metadata Tag

Once selected, you can enter the tag name you wish to use. For example: "images". When you create your job add the images tag, add any found images will be stored at bucket://CatImages/<file_name>
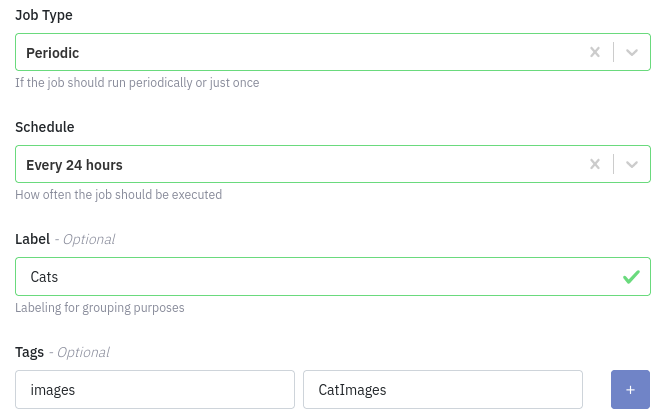
Example of a Job being created with an image tag. This view is available on the Ingress of a source.
Default Metadata Tag behaviourNote that if you select this option and then forget to add the tag, then the component will behave as if the tag name is the folder name. i.e. in the above example files will be stored in
bucket://images/<file_name>.
A side effect of this is that the tag name can be used as a default folder and then optionally overridden when creating a job.
Failure Extension
If a problem is encountered while trying to download from the URL then any content is downloaded and stored in the file as is. An optional extension can be added to the file name as well, this is configured here

In the above example, the file will have .failed appended to the stored filename
Automated File Naming
Name Rules
Cloud providers typically have limitations on the character set and length for naming files. Because URL’s can be very long and contain characters that are not supported some substitution is required; the rules are as follows
Characters are replaced:
| Character | Replacement |
|---|---|
| / | sl |
| \ | bsl |
| ? | q |
| = | eq |
| & | and |
| # | hash |
| ( | lb |
| ) | rb |
| [ | lsqb |
| ] | rsqb |
| : | Nothing - just removed |
If the full file name (i.e. the folder name + file name) has a length greater than 1000 characters then the filename is truncated and the end of the filename is replaced with a hex encoded SHA256 hash of the source URL. The hash prevents collisions between file names that would otherwise occur if the filename was simply truncated.
Example
| URL | https://scontent.cdninstagram.com/v/t51.29350-15/452924404_1101255058244198_4627717985546486366_n.jpg?stp=dst-jpg_e35_p1080x1080&_nc_ht=scontent.cdninstagram.com&_nc_cat=102&_nc_ohc=8qm1wRUaiLYQ7kNvgFdWpjA&edm=APs17CUBAAAA&ccb=7-5&ig_cache_key=MzQyMDE0NTgxMTgyMjY2OTk0OA%3D%3D.2-ccb7-5&oh=00_AYAzIGfRlgCtuUiju-CGNhTaK1FgRgCaF2q89e8yguT6Bg&oe=66A86295&_nc_sid=10d13b |
|---|---|
| File | https_sl_scontent.cdninstagram.com_sl_v_sl_t51.29350-15_sl_452924404_1101255058244198_4627717985546486366_n.jpg_q_stp_eq_dst-jpg_e35_p1080x1080_andnc_ht_eq_scontent.cdninstagram.com_andnc_cat_eq_102_andnc_ohc_eq_8qm1wRUaiLYQ7kNvgFdWpjA_and_edm_eq_APs17CUBAAAA_and_ccb_eq_7-5_and_ig_cache_key_eq_MzQyMDE0NTgxMTgyMjY2OTk0OA%3D%3D.2-ccb7-5_and_oh_eq_00_AYAzIGfRlgCtuUiju-CGNhTaK1FgRgCaF2q89e8yguT6Bg_and_oe_eq_66A86295_andnc_sid_eq_10d13b |
{kind=link}
File / Document Relationship
Files are stored with the document_id and Content-Type (where available in the source) meta-data associated with stored file.
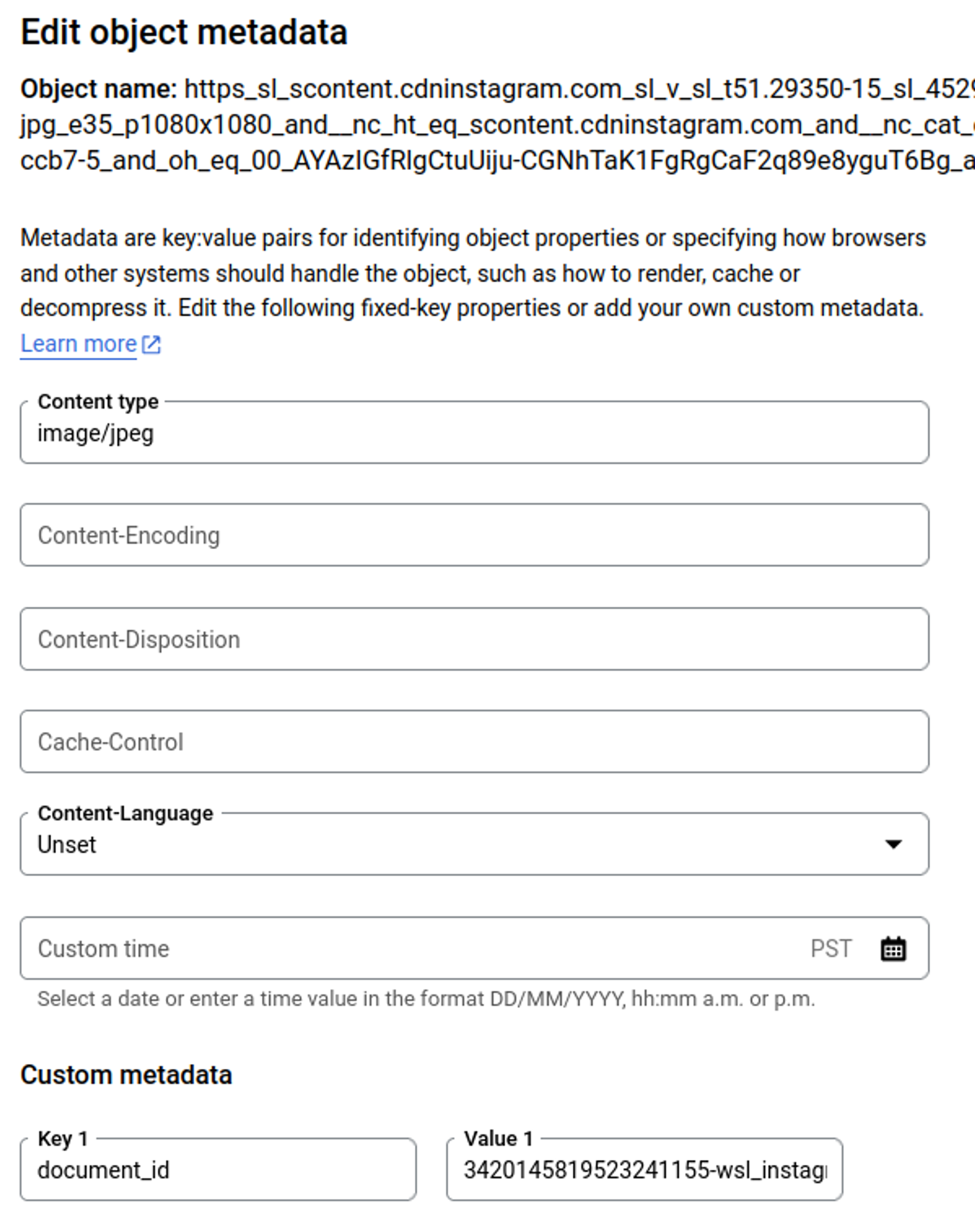
Example from Google Cloud Storage
In addition, the document json is annotated with the appropriate file reference, e.g.
{
"id": "3420145819523241155-wsl_instagram",
"doc_date": "2024-07-25T18:46:15Z",
"data_source": "wsl_instagram",
"source": {
"link": "https://instagram.com/p/C92zICMuFTD/"
},
"content": {
"body": "Meczyk z Papą!\n\nSerdeczne drapieżne pozdrowionka,\nPyza De Ru herbu Serduszko, Pseudonim „Mała Mi”, Pseudonim Madam Żenepi, Pseudonim Małe Ru, Pseudonim Madam Żużu.\n\n#Pyza #PyzadeRu #polishcat #Pyzulka #cat #catsofinstagram #polskikot #kocinka #pysiu #kotek #pyziaczek #cats #kot #koty #kotyrządzą #białoburykot #biały #bury #polskakotka #zwierzak #animals #animalphotography #pet #petsofinstagram #pets #petgram #zwierz #zwierzak #photo #photooftheday",
"location": "Powiśle",
"image_urls": [
"https://scontent.cdninstagram.com/v/t51.29350-15/452924404_1101255058244198_4627717985546486366_n.jpg?stp=dst-jpg_e35_p1080x1080&_nc_ht=scontent.cdninstagram.com&_nc_cat=102&_nc_ohc=8qm1wRUaiLYQ7kNvgFdWpjA&edm=APs17CUBAAAA&ccb=7-5&ig_cache_key=MzQyMDE0NTgxMTgyMjY2OTk0OA%3D%3D.2-ccb7-5&oh=00_AYAzIGfRlgCtuUiju-CGNhTaK1FgRgCaF2q89e8yguT6Bg&oe=66A86295&_nc_sid=10d13b"
],
"images": [
...
],
"found": "2024-07-25T18:47:09Z",
"found_by": "wsl_instagram_tag_robot",
"published": "2024-07-25T18:46:15Z",
"hashtags": [
...
],
...
},
"author": {
...
},
"enrichment": {
"language": "pl"
},
"instagram": {
...
},
"references": [
{
"provider": "azure_blob",
"kind": "original",
"file_name": "https_sl_scontent.cdninstagram.com_sl_v_sl_t51.29350-15_sl_452924404_1101255058244198_4627717985546486366_n.jpg_q_stp_eq_dst-jpg_e35_p1080x1080_and__nc_ht_eq_scontent.cdninstagram.com_and__nc_cat_eq_102_and__nc_ohc_eq_8qm1wRUaiLYQ7kNvgFdWpjA_and_edm_eq_APs17CUBAAAA_and_ccb_eq_7-5_and_ig_cache_key_eq_MzQyMDE0NTgxMTgyMjY2OTk0OA%3D%3D.2-ccb7-5_and_oh_eq_00_AYAzIGfRlgCtuUiju-CGNhTaK1FgRgCaF2q89e8yguT6Bg_and_oe_eq_66A86295_and__nc_sid_eq_10d13b",
"content_type": "image/jpeg",
"size_bytes": 169020,
"azure_blob": {
"container_name": "document-images",
"folder_name": "CatImages"
}
}
]
}
Updated about 1 month ago