
WebSightLine Instagram
The WebSightLine Instagram allows you to search for Instagram posts and/or comments
Documentation AccuracyWe try to ensure every component documentation is as accurate as possible. However as we do not manage 3rd parties product features and documentation, some 3rd party documentation may not be accurate at the time of the last update. Thank you for your understanding.
The WebSightLine Instagram component offers search capabilities within a repository containing millions of Instagram posts and comments from the past two years.
New to Datastreamer? Start here.
Unify SchemaThis data source already use Unify Schema.
How to use?
The WebSightLine Instagram is powered by the Jobs System, when interacting with the component you have the option to define your jobs queries.
Search Queries
Filters
Available filters for WebSightLine Instagram can be found in the table below:
| Filter Name | Description |
|---|---|
| query | List of keywords or a phrase to search |
| max_documents | Set a limit for the number of posts that will be fetched for the search. |
The Lucene Query is supported for this component in the query field. Here are some of the basics queries that you can try:
Keywords:
catsFields:
title:lucenePhrases:
"apache lucene"Wildcards:
tes\*Boolean operators:
cats OR dogsExamples
Search for cats or dogs
Query cats or dogs every 6 hours:
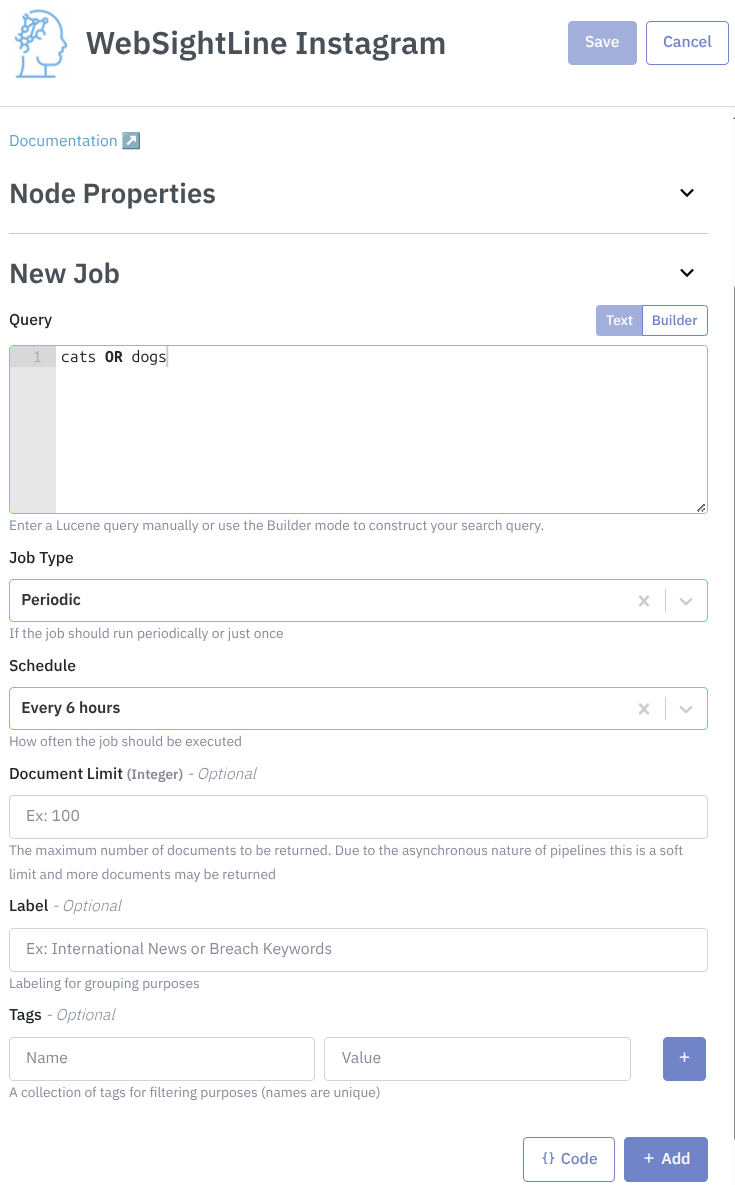
You also have the option to use the API. You can use the Code button to extract this example:
curl --location 'https://dev.api.platform.datastreamer.io/api/pipelines/{PIPELINE_ID}/components/{COMPONENT_ID}/jobs?ready=true' \
--header 'apikey: <your-api-key>' \
--header 'Content-Type: application/json' \
--data \
'{
"job_name": "57e02e42-9dd9-4390-97ed-40002ae672af",
"component_name": "wsl-instagram-ingress",
"data_source": "wsl_instagram",
"query": {
"query_string": "cats OR dogs"
},
"job_type": "periodic",
"schedule": "0 0 0/6 1/1 * ? *"
}'For more details on creating data collection jobs, see Job Management.
Additional Details
The available fields can be changed by the data provider (WebSightLines), but currently this is the possible field names.
Basic document information:
iddoc_datedata_sourcesource.link
Internal Fields:
internal.provider_document_idinternal.last_updatedinternal.annotations[].nameinternal.annotations[].valueinternal.destinations[]
Content Fields:
content.bodycontent.locationcontent.image_urls[]content.images[].urlcontent.images[].alternative_textcontent.foundcontent.found_bycontent.publishedcontent.hashtags[]content.favoritescontent.followerscontent.followingcontent.mentions[]content.last_updatedcontent.likes_countcontent.comments_count
Author Information:
author.nameauthor.bioauthor.profile_image_sourceauthor.genderauthor.urlauthor.handleauthor.verifiedauthor.is_business_account
Enrichment Data:
enrichment.languageenrichment.location_inference_country.labelenrichment.location_inference_country.confidenceenrichment.sentimentenrichment.emoji_sentiment
Instagram-specific Fields:
instagram.content_typeinstagram.user_id
These field names represent the complete structure of the Instagram post data in the documents. When using Lucene for searching, you would reference these fields with their full paths (e.g., content.body, author.name, etc.).
Updated about 2 months ago