
Big Query Writer
The Big Query Writer allow you to automatically ingests JSON data into tables (auto-schemas or predefined columns), dynamically creating/updating tables into Google BigQuery tables
The Big Query Writer component is a BigQuery egress writer that automatically streams JSON documents/data into Google BigQuery tables. It handles schema evolution by either auto-detecting JSON structures (with options to allow unknown fields) or using explicit column mappings, and dynamically creates/updates tables. It's designed as the final destination in data pipelines for analytical storage.
Prerequisites
To use Big Query Writer within your Pipelines, you will need to have the following:
- Datastreamer Portal account: With access to add a new component.
- Google Cloud Credentials: Service account JSON key with:
- BigQuery Data Editor permissions (table creation/modification)
- BigQuery User permissions (data insertion)
Setup Instructions
Step 1: Open the target Pipeline within Portal
You can create a new Pipeline, or open an existing Pipeline within Portal. You can add Big Query Writer to any Pipelines, regardless of deployment state, thanks to versioning.
Step 2: Add the Big Query Writer component from the selection menu
Select from Egress components:
Step 3: Configure the component
Components that are configured will show a green "Configured" button, while components requiring configuration as shown below.
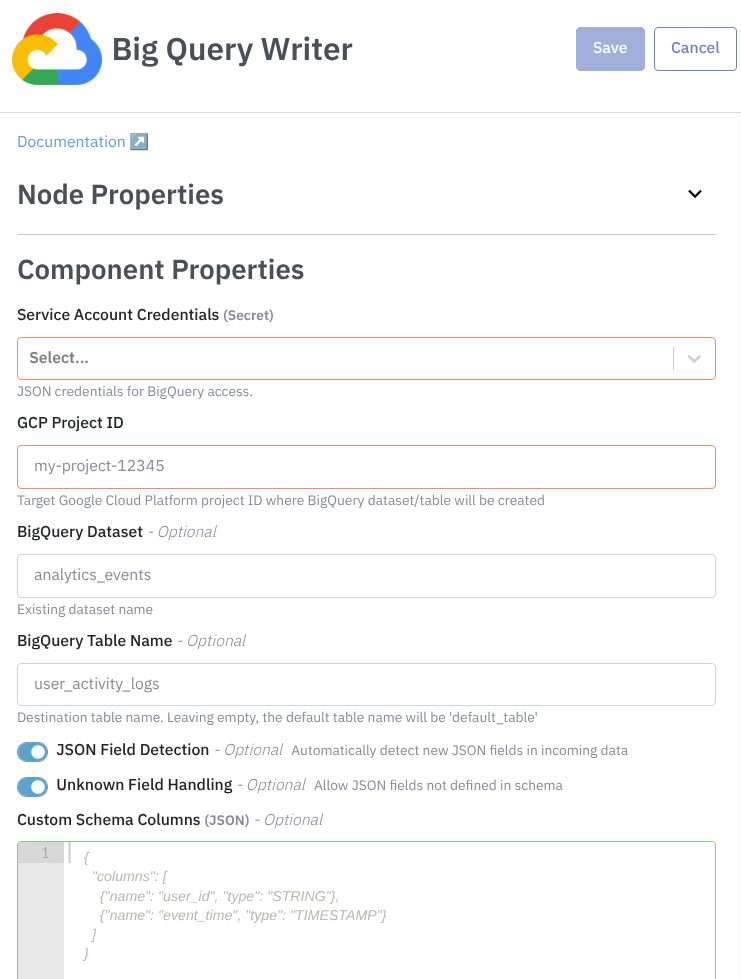
In the Service Account Credentials, you should provide the secret with the Google Cloud credentials necessary to the pipeline connect to his account.
In the GCP Project ID, you need to provide the project ID where the BigQuery dataset/table will be created.
In the BigQuery Dataset you can optionally provide the dataset name.
- Leave empty: Defaults to your organization name.
In the BigQuery Table Name you can optionally the table name.
- Leave empty: Uses
default_tablename
The JSON Field Detection let BigQuery automatically detect new fields in JSON data. Enable for:
- Social media APIs that frequently add new fields
- Exploratory analysis of raw data
- Disable if you need strict schema control.
The Unknown Field Handling allow JSON fields not predefined in schemas. Keep enabled when:
- Processing unpredictable social media data
- Using JSON Field Detection
Step 4: Deploy your Pipeline
Upon deployment, this Pipeline is fully ready to consume and process data. If you have connected your Pipeline to a live feed of data, you will notice data begin to flow upon deployment. Deploying generally takes 10-30 seconds for full rollout and diagnostics.
More details on Pipeline deployment is available here: Docs: Pipeline Deployoment.
Step 5: (Optional) Create Jobs to ingest data into your Pipeline & Testing
Creating a Job within Portal to pull data into your Pipeline is an optional step but useful to validate your Pipeline and begin using this new capability.
If you are not familiar with creating a Job, detailed instructions and information are available here. Docs: Creating Jobs via Portal or API.
The Pipeline Document Inspector is another optional addition to your Pipeline, allowing you to test and observe your setup by providing the ability to fetch pipeline documents in the browser. Docs: Document Inspector
Usage Examples
Here are real-world usage examples for this BigQuery writer component.
Cross-Platform Post Analytics
Processing:
- JSON posts from TikTok/Instagram/X from data providers → Normalized into common format using Unify
- Enriched with engagement metrics (likes, shares, views)
flowchart LR id1[fa:fa-rss Instagram] --- id3[fa:fa-handshake Unify Transformer] id4[fa:fa-rss Tiktok] --- id3[fa:fa-handshake Unify Transformer] id5[fa:fa-rss X/Twitter] --- id3[fa:fa-handshake Unify Transformer] id3 --> id2[fa:fa-database Big Query Writer]
Configuration:
- JSON Field Detection enabled
- Dataset: social_posts
Outcome:
Analysts can query the posts in a unified schema.
Trend Detection (Reddit/X)
Processing:
- Streaming posts/comments → Sentiment analysis added
data_source= subreddit name or hashtag (e.g., "r/technology", "#AI")
flowchart LR id1[fa:fa-rss X/Twitter] --- id3[fa:fa-handshake Unify Transformer] id4[fa:fa-rss Tiktok] --- id3[fa:fa-handshake Unify Transformer] id3 --> id6[fa:fa-smile Sentiment Classifier] id6 --> id2[fa:fa-database Big Query Writer]
Configuration:
- JSON Field Detection enabled
- Unknown Field Handling enabled
- Dataset: trend_alerts
Outcome:
Data team monitors spikes in retweet_count/upvote_ratio for real-time dashboards.
Schema
Unify SupportThis component has full support for the Unify schema transformation. More information on Unify is available here: Unify Transformer
FAQ & Troubleshooting
This section is currently empty, but it will be populated with frequently asked questions and troubleshooting tips as we continue to develop and improve our product. Check back here for updates and helpful information in the future.
Updated about 1 month ago