
Big Query Fixed Schema Writer
The Big Query Fixed Schema Writer ingests structured data into Google BigQuery using explicitly defined column schemas, enforcing strict type validation and consistent data formats through predefined column definitions
The Big Query Fixed Schema Writer is a strict schema egress component that streams structured data into Google BigQuery tables using explicitly defined column schemas. It enforces type safety and column definitions, making it ideal for regulated data pipelines.
Prerequisites
To use Big Query Fixed Schema Writer within your Pipelines, you will need:
- Datastreamer Portal account: With access to add new components
- Google Cloud Credentials: Service account JSON key with:
- BigQuery Data Editor permissions (table creation/modification)
- BigQuery User permissions (data insertion)
- Predefined Schema: JSON file defining column names, types, and source paths
Setup Instructions
Step 1: Open Target Pipeline
Create new or open existing Pipeline in Portal. Schema changes require new pipeline versions.
Step 2: Add Fixed Schema Writer
Select from Egress components:
Step 3: Configure Component
Components that are configured will show a green "Configured" button, while components requiring configuration as shown below.
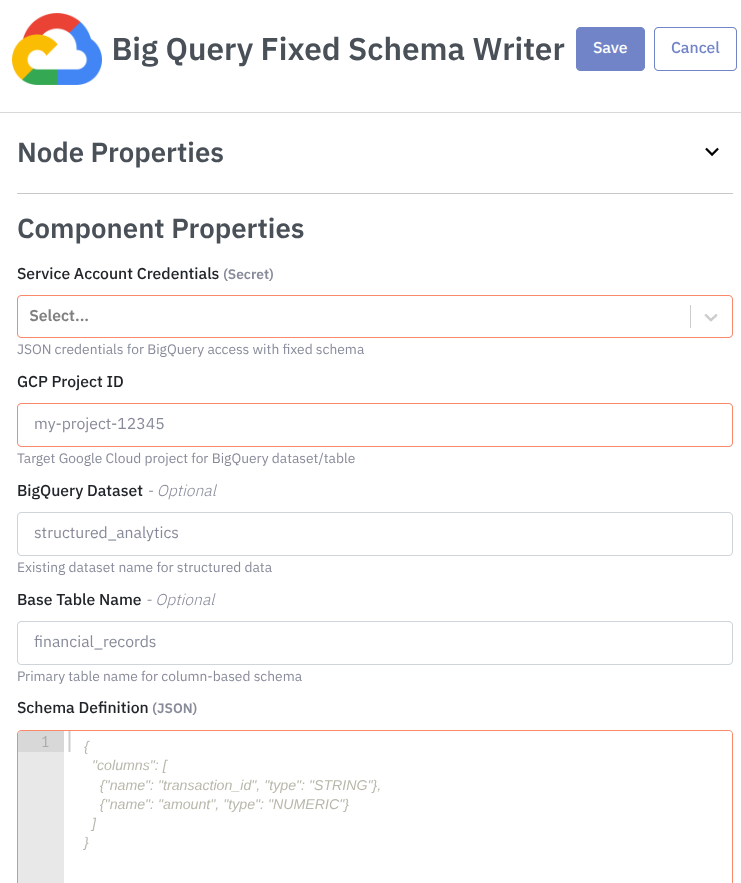
In the Service Account Credentials, you should provide the Google Cloud credentials secret.
In the GCP Project ID, fill out with the target project ID for dataset/table.
In the BigQuery Dataset, provide the existing dataset name (defaults to org name if empty).
In the Base Table Name, provide the primary table for columnar data (default: default_table)
An finally, in the Schema Definition, you should provide a JSON defining strict columns:
{
"columns": [
{"name": "transaction_id", "type": "STRING", "source_path": "id"},
{"name": "amount", "type": "NUMERIC", "source_path": "payment.amount"}
]
}Step 4: Deploy Pipeline
Upon deployment, this Pipeline is fully ready to consume and process data. If you have connected your Pipeline to a live feed of data, you will notice data begin to flow upon deployment. Deploying generally takes 10-30 seconds for full rollout and diagnostics.
More details on Pipeline deployment is available here: Docs: Pipeline Deployoment.
Step 5: (Optional) Data Validation
Creating a Job within Portal to pull data into your Pipeline is an optional step but useful to validate your Pipeline and begin using this new capability.
If you are not familiar with creating a Job, detailed instructions and information are available here. Docs: Creating Jobs via Portal or API.
The Pipeline Document Inspector is another optional addition to your Pipeline, allowing you to test and observe your setup by providing the ability to fetch pipeline documents in the browser. Docs: Document Inspector
Usage Examples
The usage examples shown are conceptual illustrations of common workflows. Actual implementations may vary depending on:
- Your specific pipeline configuration
- Available transformation components
- Data source requirements
Component names and step counts might differ in live implementations - consult our documentation for exact specifications. Examples simplified for clarity.
Social Media Brand Perception Analysis
Processing:
- Raw posts from Instagram/Twitter → Standardized format using Unify Transformer
- Sentiment analysis (AI Sentiment Classifier)
- Brand entity extraction (AI Brand Recognition)
- Category classification (AI Category Classifier)
flowchart LR id1[fa:fa-instagram Instagram] --> id2[fa:fa-handshake Unify] id3[fa:fa-twitter Twitter] --> id2 id2 --> id4[fa:fa-smile Sentiment Analysis] id4 --> id5[fa:fa-tag Brand Recognition] id5 --> id6[fa:fa-list Category Classifier] id6 --> id7[fa:fa-database Fixed Schema Writer]
Configuration:
{
"columns": [
{"name": "platform", "type": "STRING", "source_path": "source"},
{"name": "post_date", "type": "TIMESTAMP"},
{"name": "sentiment", "type": "STRING", "source_path": "enrichment.sentiment.label"},
{"name": "detected_brands", "type": "STRING", "source_path": "enrichment.brands[*].name"},
{"name": "content_category", "type": "STRING", "source_path": "enrichment.category"}
]
}Outcome:
Structured table for tracking:
- Brand mention frequency across platforms
- Sentiment trends per category (e.g., #Tech vs #Fashion)
- Historical comparisons with immutable schema versions
Brand Compliance Monitoring
Processing:
- Facebook/Reddit comments → Unified format
- Brand recognition filtering
- Sentiment scoring
- PII redaction (PrivateAI Redaction)
flowchart LR id1[fa:fa-facebook Facebook] --> id2[fa:fa-handshake Unify] id3[fa:fa-reddit Reddit] --> id2 id2 --> id4[fa:fa-eye Brand Recognition] id4 --> id5[fa:fa-smile Sentiment Analysis] id5 --> id6[fa:fa-shield PII Redaction] id6 --> id7[fa:fa-database Fixed Schema Writer]
Configuration:
{
"columns": [
{"name": "author_hash", "type": "STRING", "source_path": "author.hash"},
{"name": "brand", "type": "STRING", "source_path": "enrichment.brands[0].name"},
{"name": "compliance_status", "type": "STRING"},
{"name": "redacted_text", "type": "STRING"}
]
}Outcome:
Audit-ready storage of:
- Brand-related conversations
- Anonymized participant data
- Compliance status tracking
Schema
Unify SupportThis component has full support for the Unify schema transformation. More information on Unify is available here: Unify Transformer
FAQ & Troubleshooting
This section is currently empty, but it will be populated with frequently asked questions and troubleshooting tips as we continue to develop and improve our product. Check back here for updates and helpful information in the future.
Updated about 1 month ago