
Vetric X (Twitter) Replies
Collect X (Twitter) Replies of a tweet or a reply
The Vetric X (Twitter) Replies allows you to retrieves replies of a given tweet or the replies of a reply by using the id of that reply.
The complete Vetric documentation about their endpoint can be found in their site here.
New to Datastreamer? Start here.
Unify SchemaThis data source already use Unify Schema.
API Key
You will need a Vetric API key to use this component. If you don't have one reach out to [email protected] and our team will help you with that.
How To Use?
The component is powered by the Jobs System, when interacting with the component you have the option to define your jobs queries.
Search Query
Filters
| Filter Name | Description |
|---|---|
| query | Tweet ID |
| max_documents | Set a limit for the number of documents that will be fetched for the search. |
Examples
Example retrieving replies
Retrieves the replies from tweet with the id '1676361980486250496'.
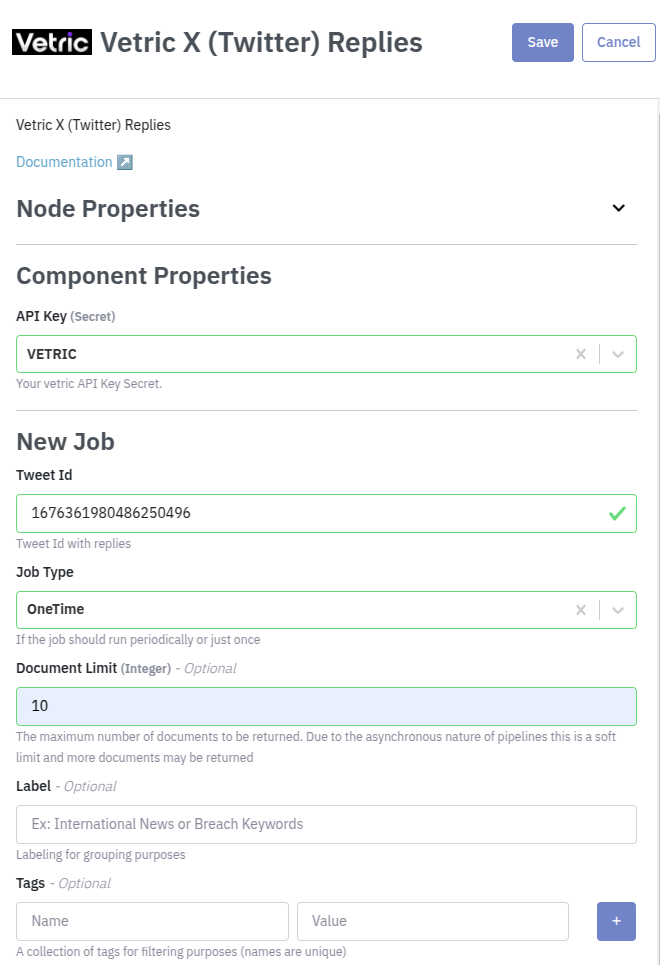
You also have the option to use the API. You can use the Code button to extract this example:
curl --location 'https://api.platform.datastreamer.io/api/pipelines/{PIPELINE_ID}/components/{COMPONENT_ID}/jobs?ready=true' \
--header 'apikey: <your-api-key>' \
--header 'Content-Type: application/json' \
--data \
'{
"job_name": "{JOB_NAME}",
"data_source": "vetric_x_replies",
"query": {
"include": [
{
"data_source": "vetric_x_replies"
}
],
"query": "1676361980486250496"
},
"job_type": "oneTime",
"max_documents": 10
}'For more details on creating data collection jobs, see Job Management.
Additional Details
Compatible Metadata Fields
| Applicable Metadata Categories | Compatible |
|---|---|
| Source | Yes |
| Content | Yes |
| Author | Yes |
| Person | No |
| Enrichment | Yes |
| Organization | No |
| Data source-specific fields? | Yes, please see the Metadata page. |
Metadata Example
{
"data_source": "vetric_x_replies",
"source": {
"link": "https://x.com/garrytan/status/1676361987578814464"
},
"id": "1676361987578814464",
"twitter": {
"post_identifier": "1676361987578814464",
"quote_count": 0,
"reply_count": 4,
"retweet_count": 10,
"user_id": "11768582",
"reply_link": "https://twitter.com/garrytan/status/1676361980486250496",
"tweet_type": "REPLY"
},
"doc_date": "2023-07-04T22:46:57Z",
"content": {
"published": "2023-07-04T22:46:57Z",
"body": "Self-authoring is the end state goal: a true founder who endures and perseveres has achieved this for themselves https://t.co/ClSdJXqzKF",
"likes_count": 105,
"views_count": 16536,
"age_restricted": false,
"image_urls": [
"https://twitter.com/garrytan/status/1676361987578814464/photo/1"
]
},
"author": {
"handle": "garrytan",
"name": "Garry Tan",
"profile_image_source": "https://pbs.twimg.com/profile_images/1775927507855998976/v1mOCezH_normal.jpg",
"verified": true,
"bio": "President & CEO @ycombinator —Founder @Initialized—designer/engineer who helps founders—YouTuber—San Francisco Democrat accelerating the boom loop—e/acc",
"location": "San Francisco, CA",
"followers": 465464,
"following": 4512,
"protected": false,
"bio_links": [
"https://youtube.com/garrytan?sub_confirmation=1"
],
"url": "https://twitter.com/garrytan"
},
"enrichment": {
"language": "en"
}
}Creating Data Collection Job
This example demonstrates a job query that will fetch replies for tweet ID 1676361980486250496 from vetric_x_replies
curl --location 'https: //api.platform.datastreamer.io/api/pipelines/{PIPELINE_ID}/components/{COMPONENT_ID}/jobs?ready=true' \
--header 'apikey: <your-api-key>' \
--header 'Content-Type: application/json' \
--data \
'{
"job_name": "my twitter data collection",
"data_source": "vetric_x_replies",
"query": {
"query": "1676361980486250496"
},
"job_type": "oneTime"
}'Important: Replace the PIPELINE_ID and COMPONENT_ID values with those corresponding to your pipeline.
NoteYou can specify the
max_documentsparameter to control the volume of data retrieved in both the main and included queries.
Include Replies of a Reply
vetric_x_replies connector supports inclusion of replies of the twitter tweet ID provided in query. Users can retrieve up to a specified number of replies for the tweet.
Creating Data Collection Job with 'Include' replies
This example demonstrates a job query that will fetch replies of a tweet with ID 1676361980486250496 and then retrieve up to 5 replies from each of the replies retrieved for tweet ID 1676361980486250496
curl --location 'https: //api.platform.datastreamer.io/api/pipelines/{PIPELINE_ID}/components/{COMPONENT_ID}/jobs?ready=true' \
--header 'apikey: <your-api-key>' \
--header 'Content-Type: application/json' \
--data \
'{
"job_name": "my twitter data collection",
"data_source": "vetric_x_replies",
"query": {
"query": "1676361980486250496",
"include": [
{
"data_source": "vetric_x_replies",
"max_documents": 5
}
]
},
"job_type": "oneTime"
}'When replies of a reply are retrieved, the reply ID they are related to, is added to content.related_post_id field.
{
"data_source": "vetric_x_replies",
"meta_data": {
"job_label": "Label",
"job_id": "job-id"
},
"source": {
"link": "https://x.com/olivia_p_walker/status/1676376503578181633"
},
"id": "1676376503578181633",
"twitter": {
"post_identifier": "1676376503578181633",
"quote_count": 0,
"reply_count": 0,
"retweet_count": 0,
"user_id": "1225191609798733830",
"reply_link": "https://twitter.com/garrytan/status/1676361980486250496",
"tweet_type": "REPLY"
},
"doc_date": "2023-07-04T23:44:38Z",
"content": {
"published": "2023-07-04T23:44:38Z",
"found_by": "51b6665e-8f4f-48be-ac18-19268b614033",
"body": "@garrytan ❤️",
"likes_count": 0,
"views_count": 682,
"mentions": [
"garrytan"
],
"related_post_id": "1676361980486250496"
},
"author": {
"handle": "olivia_p_walker",
"name": "Olivia P. Walker",
"profile_image_source": "https://pbs.twimg.com/profile_images/1840557392133496832/a6H913di_normal.jpg",
"verified": true,
"bio": "Technology and public policy analyst. Ex-BOD; VP of public policy at Confluence Ballet. @usf_spa MPA Alumni.",
"location": "Charlotte, NC; Tampa, FL ",
"followers": 5429,
"following": 335,
"protected": false,
"bio_links": [
"https://www.usf.edu/arts-sciences/departments/public-affairs/mpa/curriculum.aspx"
],
"url": "https://twitter.com/olivia_p_walker"
},
"enrichment": {
"language": "qme"
}
}Updated 11 months ago