
Databricks File Egress
Step-by step guide of how to export JSON content from your Datastreamer pipeline to Databricks using the Databricks files API.
Setting up Databricks data egress involves just a few steps.
Prerequisites
To use Databricks integration within your Pipelines, you will need to have the following:
- Datastreamer Portal account with access to add a new component.
- Databricks URI.
- Databricks Access token Databricks Access Token.
- Databricks Volume or DBFS path
Setup Instructions
Step 1: Open the target Pipeline within Portal
You can create a new Pipeline or open an existing Pipeline within the Portal.
Dynamic pipelines list page from Datastreamer Portal.
Step 2: Add a source component from the selection menu
Add a source component (ingress) to bring data into your pipeline.
You can import your own data using a variety of available connectors, such as AWS S3, Google Cloud Storage (GCS), Direct Data Upload, and more. Alternatively, you can use one of the available web data sources.
Step 3: Configure the component
Add the Databricks component to your pipeline and fill in the required configuration. Make sure to save your changes.
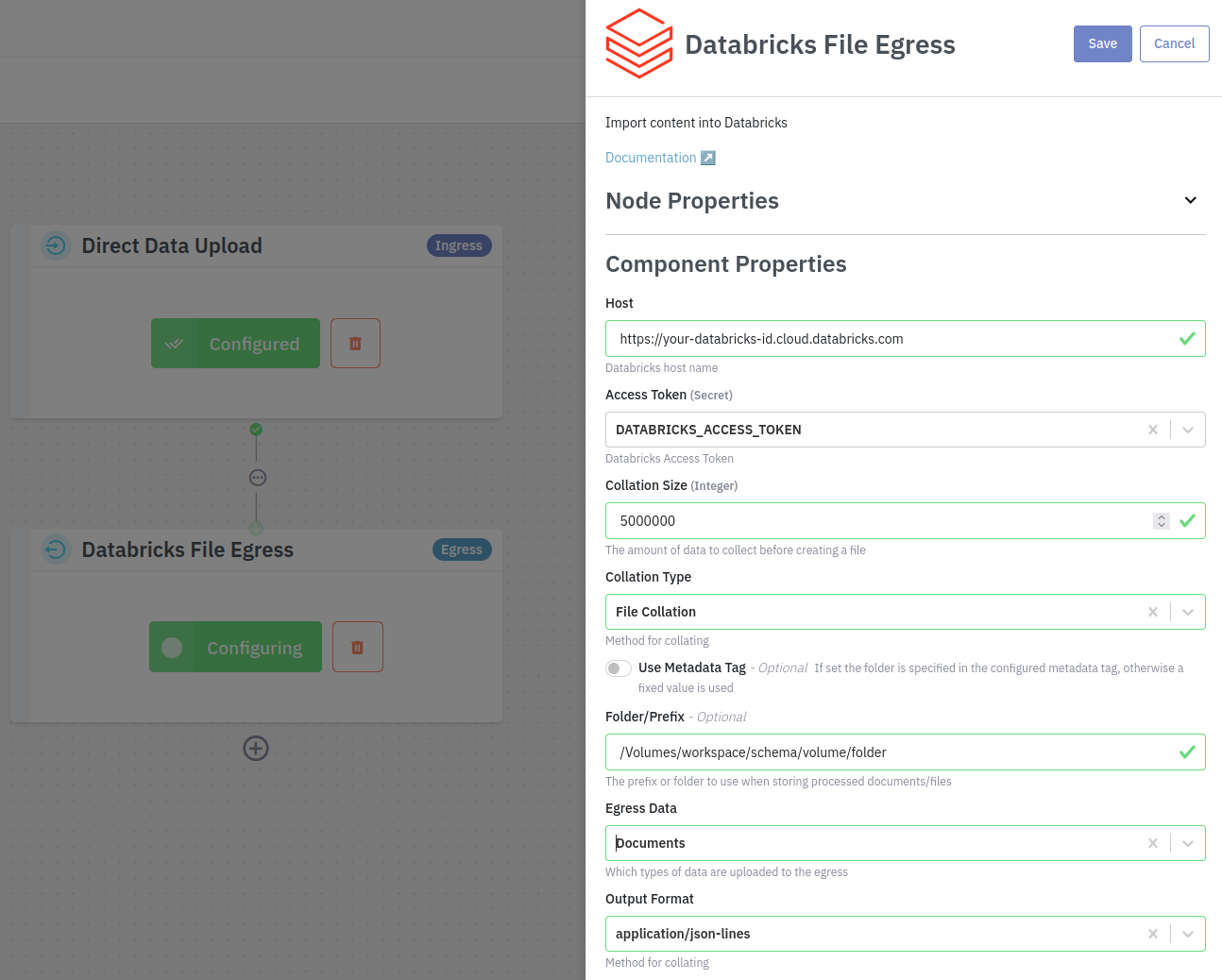
Host
The Databricks workspace URL.
AccessToken
The Personal Access Token for authenticating with Databricks.
Collation Type
This setting describes to manage uploading JSON documents to Databricks.
| Value | Description |
|---|---|
| File Collation | Documents are collated until the Collation Size limit before uploading to Databricks. |
| Per Message | Documents are uploaded immediately on receipt of a message. The number of documents per file will typically be around 100, but could be lower or higher depending on the data source. |
| Per Document | Every document will be uploaded separately. |
The default (recommended) value is File Collation
Folder/Prefix
The storage location where files will be placed on Databricks. Typically this will be of the form
/Volumes/workspace/my_schema/my_volume/my_folder
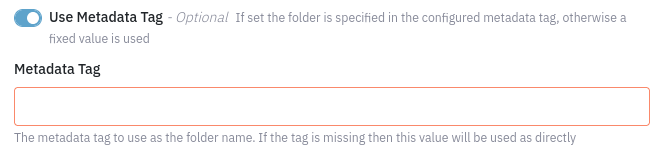
Use Metadata Tag (Optional)
Specify the Metadata Tag "name" to be used for the output folder in the bucket. The Tag "value" is configured as part of job creation. See Creating Jobs (Portal, API). If the Tag is not present on the document/file received by the Google Cloud Storage Egress component, the Metadata Tag value will be used by default as the folder name.
Egress Data
This setting describes to manage uploading JSON documents to Databricks.
| Value | Description |
|---|---|
| Documents | Only upload JSON documents |
| Files | Upload file references in the JSON documents, but not the documents themselves. |
| Documents & Files | Upload everything |
Output Format
The file format to use when uploading JSON content; options are application/json or application/json-lines
Step 4: Deploy your Pipeline
Upon deployment, this Pipeline is fully ready to consume and process data. Deploying generally takes 10-30 seconds for full rollout and diagnostics.
More details on Pipeline deployment is available here: Docs: Pipeline Deployoment
Updated about 1 month ago