
Social Voice Transcription
Convert audio or video content into accurate text transcripts using advanced AI speech recognition technology
This component processes audio or video files from a provided URL, using state-of-the-art speech recognition to generate precise text transcripts. It supports common media formats like MP4, MP3, and WAV. This is essential for creating accessible content, generating subtitles, analyzing spoken content, and archiving.
Component Configuration
Users must specify the Target URL field, which is the JSON path to the property from the incoming document, containing the URL to be analyzed (e.g., content.url).
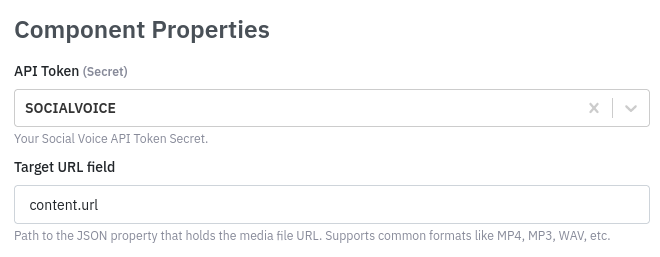
When the Social Voice API returns the response, the response is attached to the original document in a social_voice property.
Example
The final document structure would look like:
{
// Original document content...
"social_voice": {
"transcribe": {
"base_transcription": {
"segments": [
{
"end": 4.94,
"id": 0,
"start": 0.009,
"text": " A demo video is a short video that shows how a product or service works."
}
],
"text": " A demo video is a short video that shows how a product or service works."
},
"english_transcription": {
"segments": [],
"text": ""
},
"lang": "en",
"status": "ok"
}
}